阿里云服务器崩溃的影响与应对措施
网络服务故障对于企业来说,可能意味着巨大的经济损失和信誉危机。阿里云作为国内领先的云计算服务提供商,其稳定性直接关系到众多用户的业务运作。当出现服务器崩溃事件时,各种系统宕机、数据丢失等问题随之而来,这不仅给技术团队带来了压力,也让普通用户感到不安。
崩溃原因分析
考虑到各种潜在因素,造成阿里云服务器崩溃的原因通常包括硬件故障、软件漏洞、安全攻击以及流量激增等。一旦某一环节出现问题,就有可能引发连锁反应。例如。如果后端数据库发生异常,则整个应用程序都将受到影响。此外,大规模DDoS攻击也常常成为导致高可用性平台短暂瘫痪的重要元凶。

如何及时发现并处理故障
监控工具是预防和快速响应关键问题的重要手段。利用实时监控系统,可以有效捕捉异常情况,如CPU使用率过高或内存占用飙升。一旦触发警报,应立即启动自动化修复流程。同时,定期进行性能测试与评估,有助于提前识别潜在风险,从而降低突发事故的概率。
备份机制至关重要
即便采取了诸多防范措施,任何在线系统仍然会面临不可预测的问题。因此,建立完善的数据备份机制显得尤为重要。建议采用异地备份方案,将关键数据保存在不同地区,以确保灾难恢复能力。在每次更新前,都需要做好完整数据快照,为之后可能的数据回滚奠定基础。
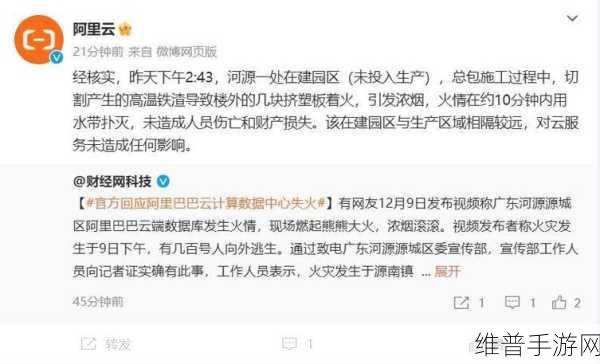
客户沟通策略优化
Crisis Management中的一个核心要素就是透明度。在遇到重大故障时,与客户保持良好的沟通尤其重要。这包括明确告知他们当前状况、预计恢复时间,以及相关补偿政策。清晰的信息传达能够增强客户信任,并减少负面舆论产生。同时,为避免同类事件再次发生,应主动分享解决方案,提高用户对公司的认可度。
安全意识提升全员参与
s 网络安全威胁日益严重,加强员工安全意识培训已变得迫在眉睫。不仅仅依靠IT部门,每个成员都有责任保护公司资产。从基本密码管理,到识别钓鱼邮件,都应该纳入培训内容。此外,还可以通过模拟演练,让员工亲身体验安全攻防过程,加深理解,提高整体抵御能力。
Error Handling and Resume Strategies
// This section can be a detailed discussion about how to handle errors in applications when cloud services fail.
// Code snippets or pseudocode demonstrating error handling could go here.
try {
// Attempt to communicate with the server
} catch (Exception e) {
logError(e); // Log the error for analysis
}
finally {
if (!serverIsUp) {
notifyAdmin(); // Notify admin of prolonged downtime
initiateBackupProcess(); // Start backup recovery process if needed
}
}