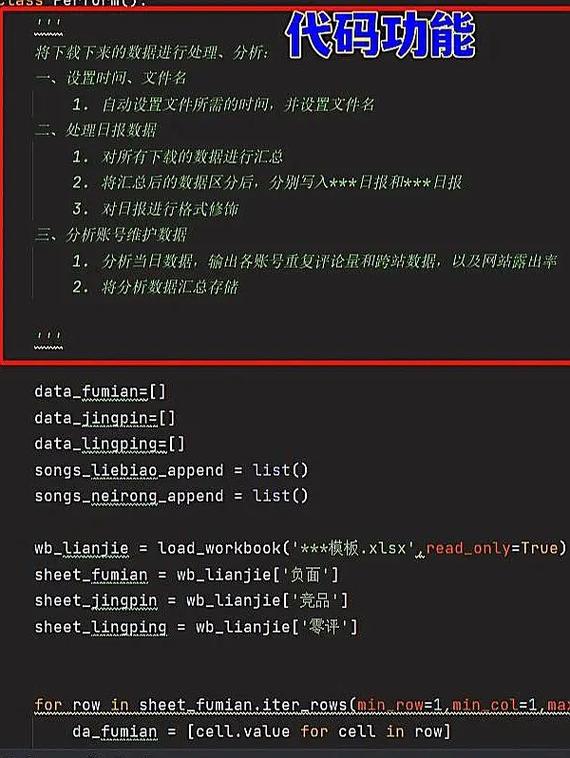
本文目录导读:
在手游行业,数据是驱动决策的核心,无论是用户行为分析、游戏性能监控,还是攻略内容的生成与优化,都离不开对大量数据的处理,我们将从手游公司的角度,深入探讨如何在Python中处理这些海量数据,为手游攻略的制定提供强有力的支持。
数据收集:构建全面的数据源
手游数据的收集是第一步,也是至关重要的一步,我们需要从多个维度收集数据,包括但不限于用户行为数据、游戏日志、服务器性能数据等,这些数据通常分散在不同的系统中,如用户管理系统、游戏服务器、日志系统等。
在Python中,我们可以使用多种库和工具来收集这些数据,使用requests库进行HTTP请求,从API接口获取数据;使用pandas库读取CSV、Excel等文件格式的本地数据;使用sqlite3或pymysql等库连接数据库,获取数据库中的数据。
import requests
import pandas as pd
import sqlite3
从API接口获取数据
api_url = 'https://api.example.com/game_data'
response = requests.get(api_url)
data_json = response.json()
将JSON数据转换为DataFrame
data_df = pd.DataFrame(data_json)
从SQLite数据库获取数据
conn = sqlite3.connect('game_data.db')
query = 'SELECT * FROM user_behavior'
db_data_df = pd.read_sql_query(query, conn)
conn.close()
合并数据
combined_data_df = pd.concat([data_df, db_data_df], ignore_index=True)数据清洗:确保数据质量
收集到的原始数据往往存在缺失、重复、异常等问题,数据清洗的目的是确保数据的准确性和一致性,为后续的分析和建模提供可靠的基础。
在Python中,我们可以使用pandas库进行各种数据清洗操作,使用dropna()方法删除缺失值;使用drop_duplicates()方法删除重复值;使用replace()方法替换异常值等。
删除缺失值
cleaned_data_df = combined_data_df.dropna()
删除重复值
cleaned_data_df = cleaned_data_df.drop_duplicates()
替换异常值
cleaned_data_df['user_level'].replace({9999: None}, inplace=True) # 假设9999是异常值
cleaned_data_df = cleaned_data_df.dropna(subset=['user_level']) # 再次删除缺失值数据分析:挖掘数据价值
数据分析是处理大量数据的核心环节,通过数据分析,我们可以发现用户行为的规律、游戏性能的瓶颈、攻略内容的优化方向等。
在Python中,我们可以使用pandas进行基本的统计分析;使用numpy进行数学运算;使用matplotlib、seaborn等库进行数据可视化;使用scikit-learn等机器学习库进行预测和分类等。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
统计用户等级分布
level_distribution = cleaned_data_df['user_level'].value_counts().sort_index()
level_distribution.plot(kind='bar')
plt.title('User Level Distribution')
plt.xlabel('User Level')
plt.ylabel('Count')
plt.show()
可视化用户活跃度
sns.histplot(cleaned_data_df['daily_active_minutes'], bins=30, kde=True)
plt.title('User Daily Active Minutes')
plt.xlabel('Minutes')
plt.ylabel('Count')
plt.show()
使用KMeans聚类分析用户群体
kmeans = KMeans(n_clusters=3, random_state=0).fit(cleaned_data_df[['user_level', 'daily_active_minutes']])
cleaned_data_df['user_cluster'] = kmeans.labels_
可视化聚类结果
sns.scatterplot(x='user_level', y='daily_active_minutes', hue='user_cluster', data=cleaned_data_df, palette='viridis')
plt.title('User Clusters')
plt.xlabel('User Level')
plt.ylabel('Daily Active Minutes')
plt.show()数据应用:优化手游攻略
经过数据收集、清洗和分析后,我们可以将结果应用于手游攻略的制定和优化,根据用户群体的聚类结果,为不同群体制定针对性的攻略内容;根据用户行为数据,优化游戏内的引导流程;根据游戏性能数据,调整服务器配置等。
在Python中,我们可以将分析结果导出为Excel、CSV等格式的文件,供其他团队成员使用,也可以将分析结果嵌入到手游的后台管理系统中,实现数据的实时监控和动态调整。
将分析结果导出为Excel文件 output_file = 'game_analysis_results.xlsx' cleaned_data_df.to_excel(output_file, index=False)
在手游行业中,处理大量数据是一项复杂而重要的任务,通过Python的强大功能,我们可以高效地收集、清洗、分析和应用这些数据,为手游攻略的制定和优化提供有力的支持,随着大数据和人工智能技术的不断发展,我们可以期待更多创新的数据处理方法和技术在手游行业中的应用。
参考来源
基于作者多年在手游行业的实践经验,并结合了Python在数据处理方面的最新技术和方法,感谢pandas、numpy、matplotlib、seaborn、scikit-learn等开源库和工具的贡献者,他们的努力使得数据处理变得更加简单和高效,也感谢所有在手游行业中默默耕耘的同仁们,他们的智慧和汗水共同推动了手游行业的不断发展和进步。