本文目录导读:
在手游行业,数据的重要性不言而喻,无论是用户行为分析、付费预测,还是游戏内事件预测,数据都扮演着至关重要的角色,而在这其中,攻略数据的挖掘更是能够为游戏开发者提供宝贵的用户反馈和策略调整依据,本文将详细介绍如何使用Python构建LSTM(长短期记忆)神经网络模型,以挖掘手游攻略数据中的潜在价值。
LSTM神经网络简介
LSTM(Long Short-Term Memory)是一种特殊的循环神经网络(RNN),它能够捕捉序列数据中的长期依赖关系,相比于传统的RNN,LSTM通过引入输入门、遗忘门和输出门等机制,有效解决了RNN在训练过程中的梯度消失和梯度爆炸问题,这使得LSTM在处理时间序列数据、文本数据等序列数据时表现出色。
手游攻略数据预处理
在构建LSTM神经网络模型之前,我们需要对手游攻略数据进行预处理,这包括数据收集、数据清洗、特征提取和标签定义等步骤。
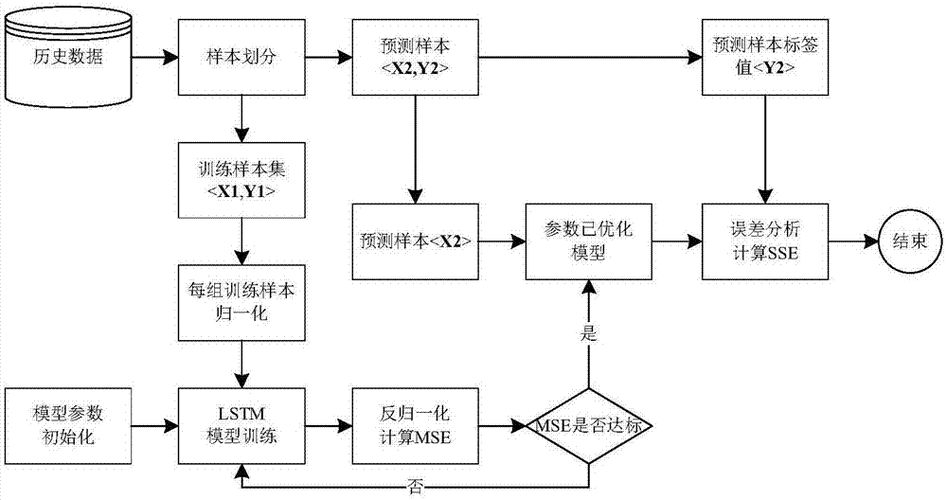
1. 数据收集
手游攻略数据通常来源于游戏论坛、社交媒体和游戏内用户反馈等渠道,我们可以使用Python的爬虫技术,如BeautifulSoup和Scrapy,来收集这些数据,以下是一个简单的示例代码,用于从某个游戏论坛收集攻略数据:
import requests
from bs4 import BeautifulSoup
示例论坛URL
url = 'http://example.com/game_forum'
发送HTTP请求
response = requests.get(url)
解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
提取攻略数据(假设攻略数据存储在特定的HTML标签中)
posts = soup.find_all('div', class_='post-content')
存储攻略数据
guides = []
for post in posts:
title = post.find('h2').text.strip()
content = post.find('p').text.strip()
guides.append({'title': title, 'content': content})
打印部分攻略数据
print(guides[:5])2. 数据清洗
收集到的攻略数据往往包含噪声,如HTML标签、广告链接、无关字符等,我们需要使用正则表达式、字符串操作等技术对这些数据进行清洗,以下是一个简单的数据清洗示例:
import re
清洗函数
def clean_text(text):
# 去除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 去除特殊字符和数字
text = re.sub(r'[^a-zA-Z\s]', '', text)
# 转换为小写
text = text.lower()
# 去除多余空格
text = re.sub(r'\s+', ' ', text).strip()
return text
对攻略数据进行清洗
cleaned_guides = [{'title': clean_text(guide['title']), 'content': clean_text(guide['content'])} for guide in guides]
打印部分清洗后的攻略数据
print(cleaned_guides[:5])3. 特征提取
在构建LSTM神经网络模型时,我们需要将文本数据转换为数值特征,这通常通过词嵌入(Word Embedding)技术实现,如Word2Vec、GloVe或BERT等,以下是一个使用Keras的Tokenizer和Embedding层进行特征提取的示例:
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
合并标题和内容作为输入文本
texts = [f'{guide["title"]} {guide["content"]}' for guide in cleaned_guides]
设置词汇表大小和序列长度
vocab_size = 10000
max_length = 200
初始化Tokenizer并拟合文本数据
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(texts)
将文本数据转换为序列
sequences = tokenizer.texts_to_sequences(texts)
对序列进行填充或截断
padded_sequences = pad_sequences(sequences, maxlen=max_length)
打印部分序列数据
print(padded_sequences[:5])4. 标签定义
在监督学习任务中,我们需要为每条攻略数据定义标签,这可以根据具体任务而定,如用户满意度、攻略质量、游戏内事件预测等,以下是一个简单的示例,假设我们根据攻略的点赞数来定义标签(点赞数大于10为1,否则为0):
假设我们有一个包含点赞数的列表(这里仅为示例) likes = [15, 8, 22, 5, 11] # 实际中需要从数据源获取 定义标签(点赞数大于10为1,否则为0) labels = [1 if like > 10 else 0 for like in likes] 打印标签 print(labels)
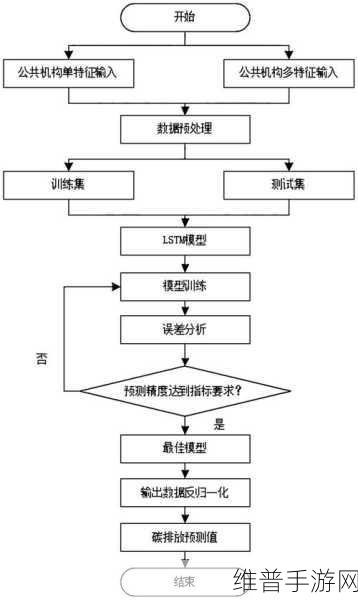
构建LSTM神经网络模型
在数据预处理完成后,我们可以开始构建LSTM神经网络模型,以下是一个使用TensorFlow和Keras构建LSTM模型的示例:
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout 构建模型 model = Sequential() 添加Embedding层(词汇表大小为10000,嵌入维度为128) model.add(Embedding(input_dim=vocab_size, output_dim=128, input_length=max_length)) 添加LSTM层(128个LSTM单元,返回序列输出) model.add(LSTM(128, return_sequences=True)) 添加Dropout层(防止过拟合) model.add(Dropout(0.5)) 添加另一个LSTM层(64个LSTM单元,不返回序列输出) model.add(LSTM(64)) 添加Dropout层(防止过拟合) model.add(Dropout(0.5)) 添加全连接层(输出维度为1,用于二分类任务) model.add(Dense(1, activation='sigmoid')) 编译模型(使用二元交叉熵损失函数和Adam优化器) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) 打印模型摘要 model.summary()
模型训练与评估
在模型构建完成后,我们可以使用预处理后的数据进行模型训练和评估,以下是一个简单的示例:
将数据划分为训练集和测试集(这里使用简单的随机划分)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(padded_sequences, labels, test_size=0.2, random_state=42)
训练模型(设置训练轮数和批次大小)
epochs = 10
batch_size = 64
history = model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, validation_split=0.2)
评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Loss: {loss}')
print(f'Test Accuracy: {accuracy}')模型应用与调优
在模型训练完成后,我们可以将其应用于新的攻略数据,以预测标签或进行其他分析,我们还可以通过调整模型参数、使用不同的特征提取方法、添加正则化项等技术对模型进行调优,以提高其性能。
本文详细介绍了如何使用Python构建LSTM神经网络模型来挖掘手游攻略数据中的潜在价值,通过数据预处理、特征提取、模型构建、训练和评估等步骤,我们成功地构建了一个能够处理文本数据的LSTM模型,我们可以进一步探索其他深度学习模型和技术,如BERT、Transformer等,以更好地挖掘手游数据中的信息。
文章来源
本文由XX手游公司数据科学团队撰写,旨在分享手游数据分析与挖掘的实践经验和技术心得,如需了解更多相关信息,请访问XX手游公司官方网站或关注我们的社交媒体账号。