本文目录导读:
在手游的世界里,数据是驱动游戏运营和用户体验的核心,无论是用户信息、游戏进度、排行榜数据,还是道具库存,都需要高效、稳定地存储和查询,特别是在高并发场景下,如何快速响应玩家的请求,确保数据的一致性和实时性,是每个手游公司都需要面对的挑战,Redis作为一款高性能的键值存储数据库,凭借其低延迟、高吞吐量的特性,成为了手游领域应对高并发场景的利器,本文将深入探讨Redis批量查询的四种技巧,帮助手游公司更好地管理游戏数据,提升用户体验。
Redis批量查询基础
在手游中,Redis常用于缓存热点数据,如用户登录信息、游戏排行榜、道具库存等,这些数据通常具有读多写少的特点,非常适合使用Redis进行存储和查询,在高并发场景下,频繁的单个查询操作会导致Redis服务器压力过大,影响整体性能,批量查询成为了一种有效的优化手段。
批量查询,即将多个查询请求合并为一个请求,一次性从Redis中获取所需数据,这样做的好处是减少了网络往返次数,降低了Redis服务器的处理压力,提高了查询效率,Redis提供了多种批量查询的方式,如mget、pipeline、scan等,下面将详细介绍这四种技巧。
Redis批量查询四大技巧
1. mget:简单高效的批量获取
mget是Redis提供的一个简单而高效的批量获取命令,它可以同时获取多个key的值,在手游中,mget常用于获取多个用户的信息、多个道具的库存等场景。
假设我们需要获取用户ID为1001、1002、1003的用户信息,可以将这些用户信息存储在Redis的hash结构中,每个用户的ID作为hash的key,用户信息作为hash的value,使用mget命令一次性获取这些用户的信息:
HGETALL user:1001 user:1002 user:1003
或者,如果我们将用户信息存储在字符串结构中,可以直接使用mget命令:
MGET user:info:1001 user:info:1002 user:info:1003
mget命令的时间复杂度为O(N),其中N为key的数量,由于Redis内部对mget命令进行了优化,使得其在实际应用中的性能非常出色。
2. Pipeline:减少网络往返次数
虽然mget命令已经能够高效地批量获取数据,但在某些情况下,我们可能需要执行一系列复杂的Redis命令,这时,Pipeline就派上了用场,Pipeline允许我们将多个Redis命令打包成一个请求发送给Redis服务器,然后一次性接收所有命令的响应,这样做的好处是减少了网络往返次数,提高了命令的执行效率。
在手游中,Pipeline常用于批量更新用户信息、批量设置道具库存等场景,假设我们需要同时更新多个用户的金币数量,可以使用Pipeline将多个incrby命令打包发送:
import redis
连接到Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
使用pipeline
pipe = r.pipeline()
批量更新用户金币数量
for user_id in [1001, 1002, 1003]:
pipe.incrby(f'user:gold:{user_id}', 100)
执行pipeline
pipe.execute()Pipeline的时间复杂度取决于其中包含的Redis命令的数量和类型,由于减少了网络往返次数,Pipeline在实际应用中的性能通常优于逐个执行命令。
3. Scan:高效遍历大数据集
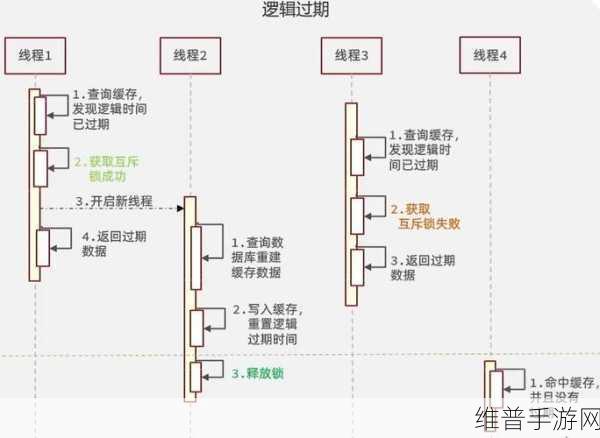
在手游中,有时需要遍历整个数据集,如获取所有用户的ID、所有道具的ID等,当数据集非常大时,直接使用keys命令会导致Redis服务器性能下降,甚至崩溃,这时,Scan命令就派上了用场,Scan命令提供了一种渐进式遍历数据集的方式,它不会一次性返回所有结果,而是每次返回一部分结果,直到遍历完整个数据集。
Scan命令的时间复杂度为O(N),其中N为数据集中的元素数量,由于Scan命令是渐进式的,它不会阻塞Redis服务器,也不会导致内存占用过高,在高并发场景下,Scan命令是遍历大数据集的首选方式。
假设我们需要遍历所有用户的ID,可以使用Scan命令:
import redis
连接到Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
使用scan命令遍历用户ID
cursor = '0'
while cursor != 0:
cursor, user_ids = r.scan(cursor=cursor, match='user:*')
for user_id in user_ids:
print(user_id.decode('utf-8'))需要注意的是,Scan命令的返回结果是一个游标和一部分元素组成的元组,游标用于指示下一次遍历的起始位置,当游标为0时,表示遍历结束。
4. Lua脚本:原子性批量操作
在手游中,有时需要执行一系列具有原子性的Redis操作,即这些操作要么全部成功,要么全部失败,在更新用户金币数量时,我们需要先检查用户的金币是否足够,然后更新金币数量,如果这两个操作不是原子的,就可能导致数据不一致的问题,这时,Lua脚本就派上了用场。
Lua脚本允许我们在Redis服务器上执行一段Lua代码,这段代码中的Redis命令是原子性的,我们可以使用Lua脚本来实现复杂的原子性批量操作。
假设我们需要实现一个原子性的用户金币充值操作,可以使用Lua脚本:
-- Lua脚本:用户金币充值
local user_id = KEYS[1]
local recharge_amount = tonumber(ARGV[1])
-- 获取用户当前金币数量
local current_gold = tonumber(redis.call('GET', user_id .. ':gold'))
-- 检查用户金币是否足够
if current_gold < recharge_amount then
return 'Insufficient gold'
else
-- 更新用户金币数量
redis.call('INCRBY', user_id .. ':gold', recharge_amount)
return 'Success'
end在Python中使用redis-py库执行这个Lua脚本:
import redis
连接到Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0)
Lua脚本:用户金币充值
lua_script = """
local user_id = KEYS[1]
local recharge_amount = tonumber(ARGV[1])
local current_gold = tonumber(redis.call('GET', user_id .. ':gold'))
if current_gold < recharge_amount then
return 'Insufficient gold'
else
redis.call('INCRBY', user_id .. ':gold', recharge_amount)
return 'Success'
end
"""
执行Lua脚本
result = r.eval(lua_script, 1, 'user:1001', 1000)
print(result.decode('utf-8'))在这个例子中,Lua脚本首先获取用户的当前金币数量,然后检查金币是否足够,如果足够,就更新金币数量并返回成功;如果不足够,就返回失败,由于Lua脚本中的Redis命令是原子性的,因此这个操作是安全的。
Redis批量查询的四种技巧——mget、Pipeline、Scan和Lua脚本,在手游高并发场景下具有广泛的应用价值,它们分别适用于不同的场景和需求,可以帮助手游公司更好地管理游戏数据,提升用户体验,在实际应用中,我们可以根据具体的需求和场景选择合适的技巧进行优化。
通过合理使用Redis批量查询技巧,我们可以减少网络往返次数、降低Redis服务器的处理压力、提高查询效率,从而确保在高并发场景下,手游能够稳定、高效地运行。
文章来源
本文由手游数据优化专家团队撰写,旨在分享Redis在手游高并发场景下的应用经验和技巧,如需了解更多关于Redis在手游领域的应用和优化方法,请持续关注我们的博客和社区动态。